
本文信息源自网上公开课的知识笔记和自己的一些拓展学习、补充。
0x01. 黑产业检测研究介绍
黑产业介绍
常见分类:
- 金融欺诈(如:电信诈骗)
- 贩卖服务,贩卖工具(如:为犯罪集团提供服务和工具开发等)
- 非法交易(如:非开源数据、违禁品等)
特点:
规模庞大,影响恶劣,行踪隐蔽。
据某2018年的研究报告显示,2017年我国黑产从业人员超过150万人(算是一些正好擦边的从业者,数量只会更多),年产值达千亿级别。
黑产展现形式
Promotion Attack:攻击者利用网站的弱点注入非法广告内容的攻击。(常见的比如高权重网站的留言板、search等)

应对思路:通过批量扫描网页页面,识别域名与内容是否存在不一致,以追踪攻击者。
BulletProof Hosting(BPH):简称“防弹主机”服务,为犯罪份子提供了可抵抗非法活动投诉的技术基础架构。
比如提供黑产网站域名和主机服务,使其能绕过运营商的限制,发送垃圾邮件和垃圾信息,或者组建钓鱼网站、组件僵尸网络等。(当然,我国因为有备案制度限制,所以在国内发布垃圾消息的黑产网站基本溯源后IP都分布在境外或国内某地区)
应对思路:提取BPH的动态特征,进行特征提取。
Black Hat SEO:黒帽搜索引擎优化,这个是最广为人知的黑产形式之一。常见技术有:隐形文本链接,关键词填充,链接工厂,webshell挂暗链等。
相对较新的黑帽优化手段是蜘蛛池(Spider Pool)(PS:其实也流行好几年了)。
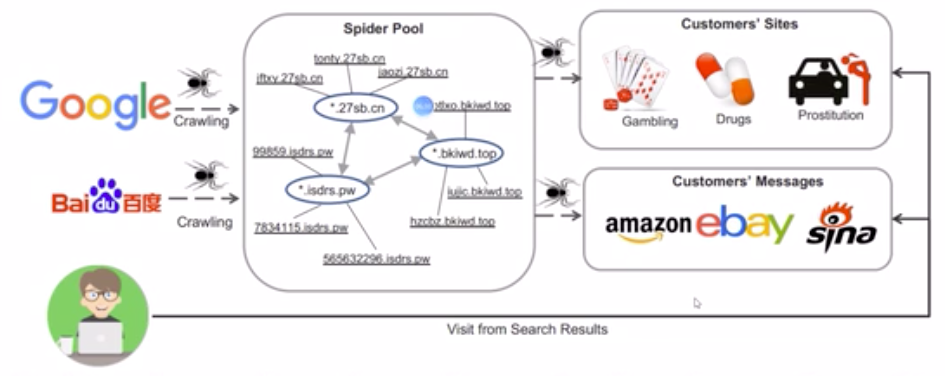
图上是搜索引擎蜘蛛进入网站后,网站不断动态生成一堆子域名和页面,让搜索引擎蜘蛛在站群中一直爬来爬去,无法绕出,以此提高目标页面的收录率和排名。
更通俗的解释是:蜘蛛池就是一堆由垃圾域名组成的站群,在每个站点下都生成海量页面(抓一堆文本内容相互组合),页面模板与正常网页没多大区别。由于每个站点都有海量的页面,所以整个站群的蜘蛛总抓取量也是巨大的。给未收录的页面引蜘蛛,比如在站群正常网页的模板中单独开一个DIV,放上未收录网页的链接(可用程序控制,已收录的链接就不再展示于此,只不断堆积没有收录的链接),服务器不设缓存,使得蜘蛛每次访问这块DIV中展现的链接都是不一样的。
蜘蛛池给那些未收录的页面,在短时间内提供大量的真实的外链,是页面入口曝光多了,被抓取几率就增加,收录率自然会提升,又因为是外链,所以在排名上也有一定的正向加分。
丝绸之路(Silk Road):和我们历史课学的那个名词没有任何关系。是一个在线黑市网站,首个被世人所知的现代暗网市场,曾经是著名的非法交易平台,主要使用比特币进行交易(现已被FBI端掉)。
基于黑词进行交易:通过使用“黑词”(也叫“黑话”)进行非法交易。比如贩卖枪支团伙在交易中一般称枪支为“狗”,称子弹为“狗粮”。加拿大某些人以“lemon”代指大麻。
什么是黑产词?
1 | “黑产词”是伴随黑产出现的产品同义词及违法产品本身的关键词的统称。非法商贩和买家通过协定新的词汇表示一种产品,以此躲避监管。 |
一般而言,在分析黑产交易过程中最大的困难是理解他们如何交流。因此,相当多的黑词是“难发现、难理解”的,毕竟对于黑产交易者来说,识别度越低越安全。
比如:
1 | 球板 ball board -- 球类运动的职业签赌版,属于违法犯罪行为。 |
更多内容可见黑产研究(地下产业研究)笔记
0x02.黑词挖掘——基于SEO
那么如何捕捉黑产行踪呢?现今的一些机器学习技术可以提供不少帮助。
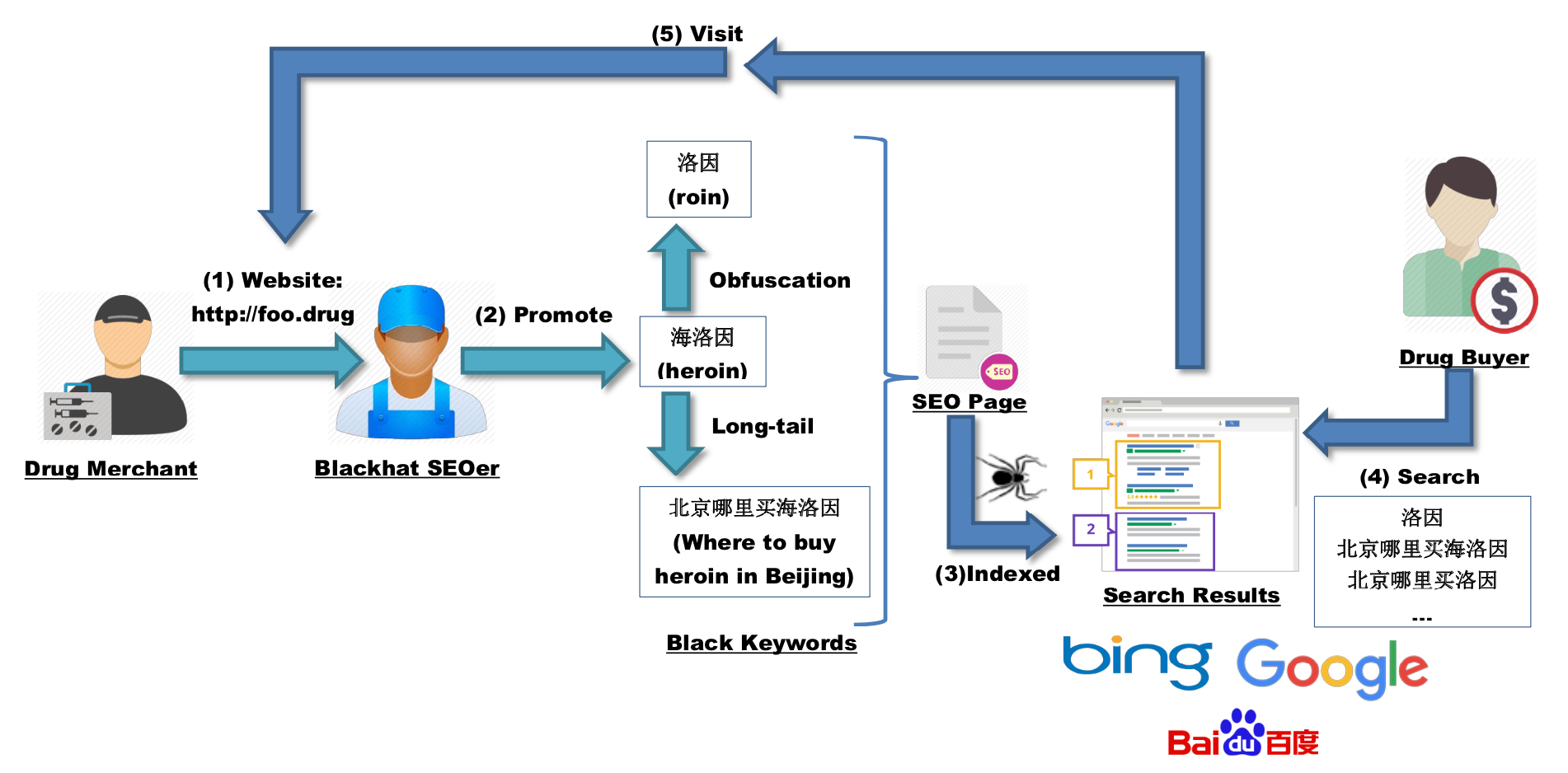
黑产商人将商品页面交给黑帽SEO做优化,黑帽SEO对关键词做“优化”(谐音、长尾词等)后提高黑产产品页面和黑词排名。
如果通过搜索能找到一小批黑词,就能以此挖掘更多的黑词。
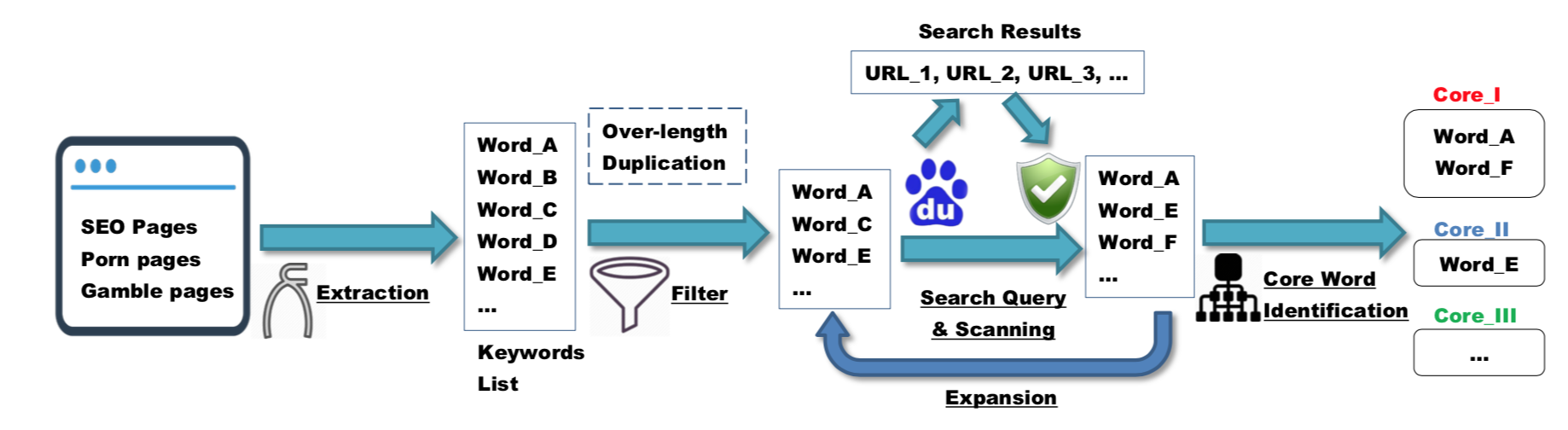
通过爬取页面数据清洗和识别(如:href锚链接的文本),利用NLP相关技术,整理出真正的黑词并进行分类和分级。
数据清洗思路:
合法的关键词往往会被黑词更长
搜索引擎会帮助我们标记恶意的页面
利用搜索引擎推荐的相关搜索词继续挖掘黑词
识别核心词语,并对相似的黑词进行聚类
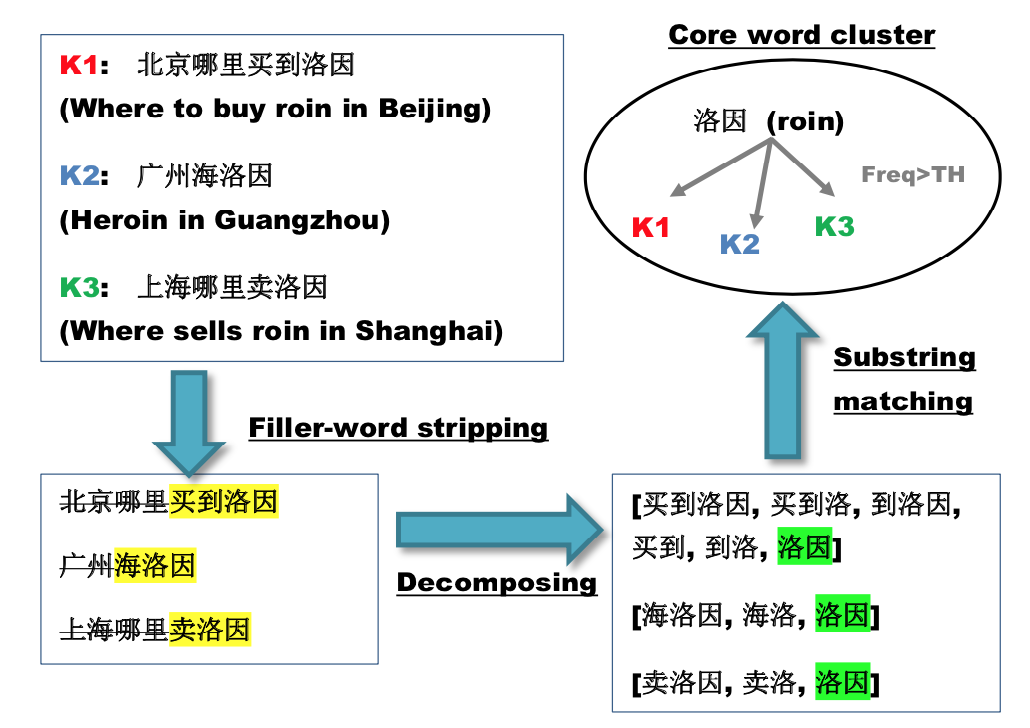
- 使用NLP技术去掉无关词语,如停用词(是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words,即停用词)、地点、无意义标点符号、虚词、emoji等。
- 找到共同的子串。
0x03.黑词检测——基于语义
部分词语在不用语境下有不同词义。如可乐在黑市上可能代指“可卡因”,葡萄可能代指“大麻”,老鼠在黑客交易中代指“木马”。可以利用语境分析来进行识别。

如上图例子中,根据红框关键词和上下文语境,可以自然理解到rat在这里不是指老鼠,而是指木马程序。
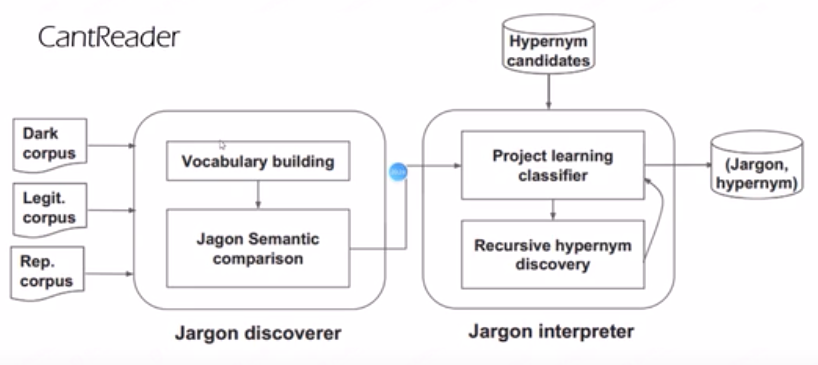
一个用于黑词识别分析的模型架构,使用多种词库,包含关系判断模型(所以需要使用机器学习的相关技术,这里涉及的内容没有机器学习和自然语言处理基础的人理解起来还是比较困难的,建议认真阅读论文原文,最后的REF)。

拓展阅读
